Writing An Hadoop Mapreduce Program In Perler
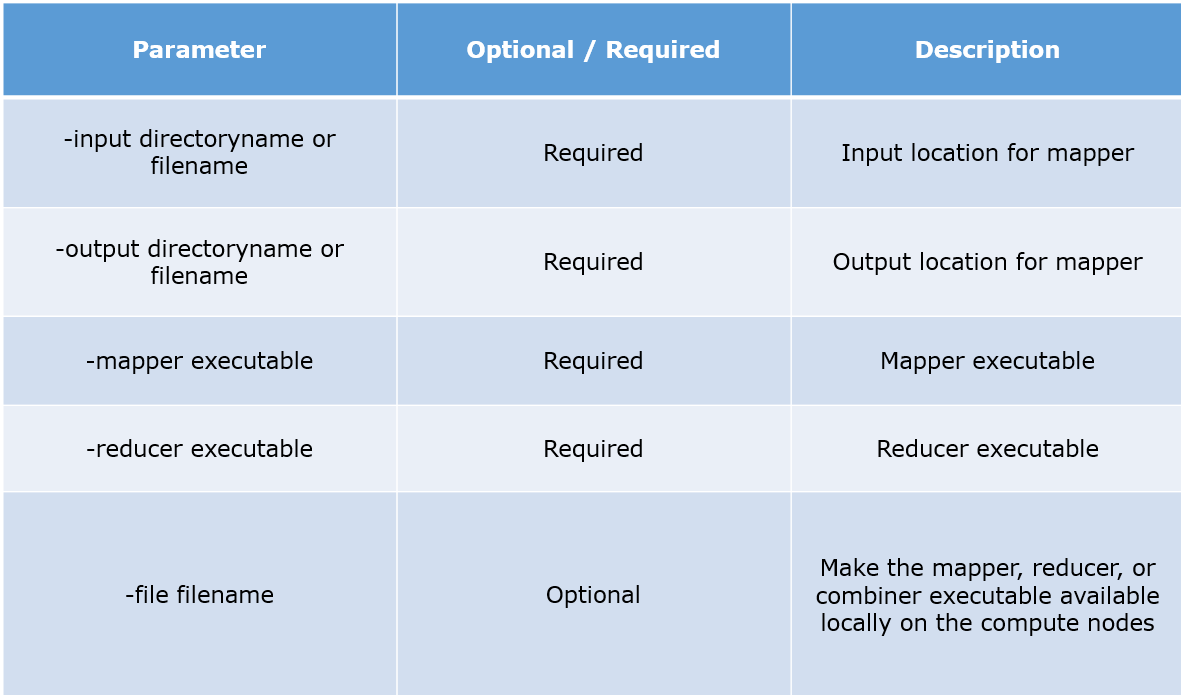
Run custom MapReduce programs • • 5 minutes to read • Contributors • • • • In this article Hadoop-based big data systems such as HDInsight enable data processing using a wide range of tools and technologies. The following table describes the main advantages and considerations for each one.
Within Hadoop Pig can run in local mode or mapreduce mode. Local mode is suited for processing small amounts of data. Local mode does not require Hadoop and hdfs. The driver class is responsible for setting our MapReduce job to run in Hadoop. In this class, we specify job name, data type of input/output and names of mapper and reducer classes.
Query mechanism Advantages Considerations Hive using HiveQL • An excellent solution for batch processing and analysis of large amounts of immutable data, for data summarization, and for on demand querying. It uses a familiar SQL-like syntax. • It can be used to produce persistent tables of data that can be easily partitioned and indexed. • Multiple external tables and views can be created over the same data. • It supports a simple data warehouse implementation that provides massive scale-out and fault-tolerance capabilities for data storage and processing. • It requires the source data to have at least some identifiable structure. • It is not suitable for real-time queries and row level updates.
It is best used for batch jobs over large sets of data. • It might not be able to carry out some types of complex processing tasks. Pig using Pig Latin • An excellent solution for manipulating data as sets, merging and filtering datasets, applying functions to records or groups of records, and for restructuring data by defining columns, by grouping values, or by converting columns to rows. • It can use a workflow-based approach as a sequence of operations on data. • SQL users may find Pig Latin is less familiar and more difficult to use than HiveQL. • The default output is usually a text file and so can be more difficult to use with visualization tools such as Excel.

Typically you will layer a Hive table over the output. Custom map/reduce • It provides full control over the map and reduce phases and execution.
• It allows queries to be optimized to achieve maximum performance from the cluster, or to minimize the load on the servers and the network. • The components can be written in a range of well-known languages. • It is more difficult than using Pig or Hive because you must create your own map and reduce components. • Processes that require joining sets of data are more difficult to implement.
• Even though there are test frameworks available, debugging code is more complex than a normal application because the code runs as a batch job under the control of the Hadoop job scheduler. HCatalog • It abstracts the path details of storage, making administration easier and removing the need for users to know where the data is stored. • It enables notification of events such as data availability, allowing other tools such as Oozie to detect when operations have occurred. • It exposes a relational view of data, including partitioning by key, and makes the data easy to access. • It supports RCFile, CSV text, JSON text, SequenceFile, and ORC file formats by default, but you may need to write a custom SerDe for other formats. Descubre tu perfil personalidad eneagrama pdf merge.
• HCatalog is not thread-safe. • There are some restrictions on the data types for columns when using the HCatalog loader in Pig scripts.